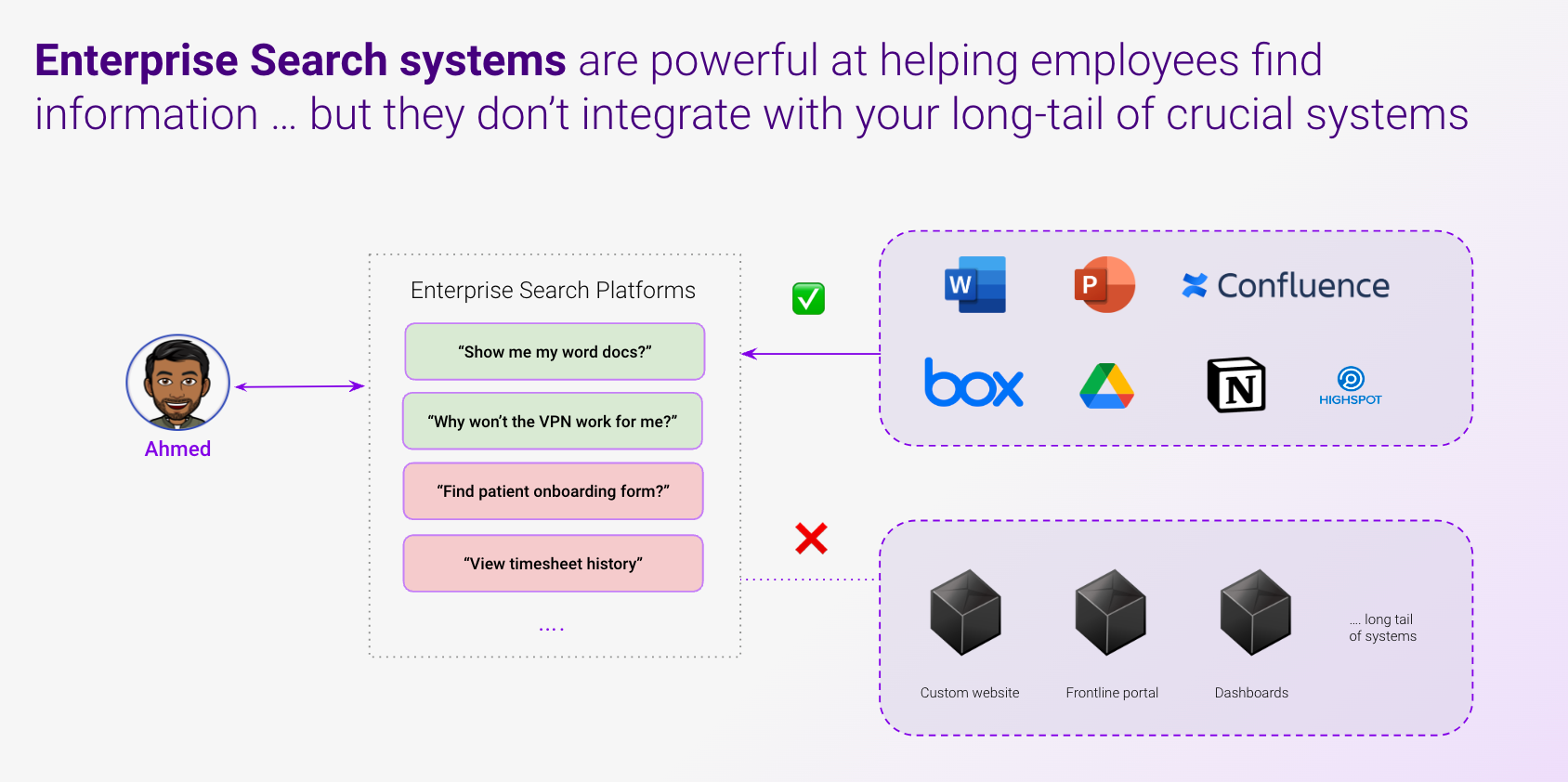
Enterprise Search systems are powerful at helping employees find important information
An organization can have millions of documents spread across multiple systems. Historically, this information was impossible for average employees to consume because of several factors: lack of self-service culture, failing search tools, disparate logins & challenging UIs. Large number of documents in a maze-like setup meant that most employees were unlikely to find information they needed to be effective.
Employees needed an easy, federated way to search & navigate internal information. In the last 5 years, powerful Enterprise Search systems were born. An effective Enterprise Search system is:
- Full integrated: Retrieves content from all content management system
- Reliable: Retrieves the right documents at the right time
- Easy to use: Provides a simple interface to employees
Unfortunately, enterprise search systems are rarely integrated with all content systems.
Lack of custom integrations & out-of-date information break Enterprise Search
Most enterprise search systems today have integrations to popular tools like Sharepoint, Google Drive, Confluence — but they often lack integrations to the long tail of business systems. Everything can’t be stored on popular tools, many additional knowledge systems are required to match your organization’s intricate needs. Let’s take a few examples:
- A home-grown content management system that powers your website
- A custom portal containing operating procedures for all your frontline workers
- A repository of compliance docs housing all your legal policies
- An internal database that stores all your customer engagement insights … & more
Being able to access & understand this knowledge is crucial for your employees. But as soon as your knowledge management exits mainstream tools — your ability to leverage Enterprise Search products is impeded by the lack of data integrations.
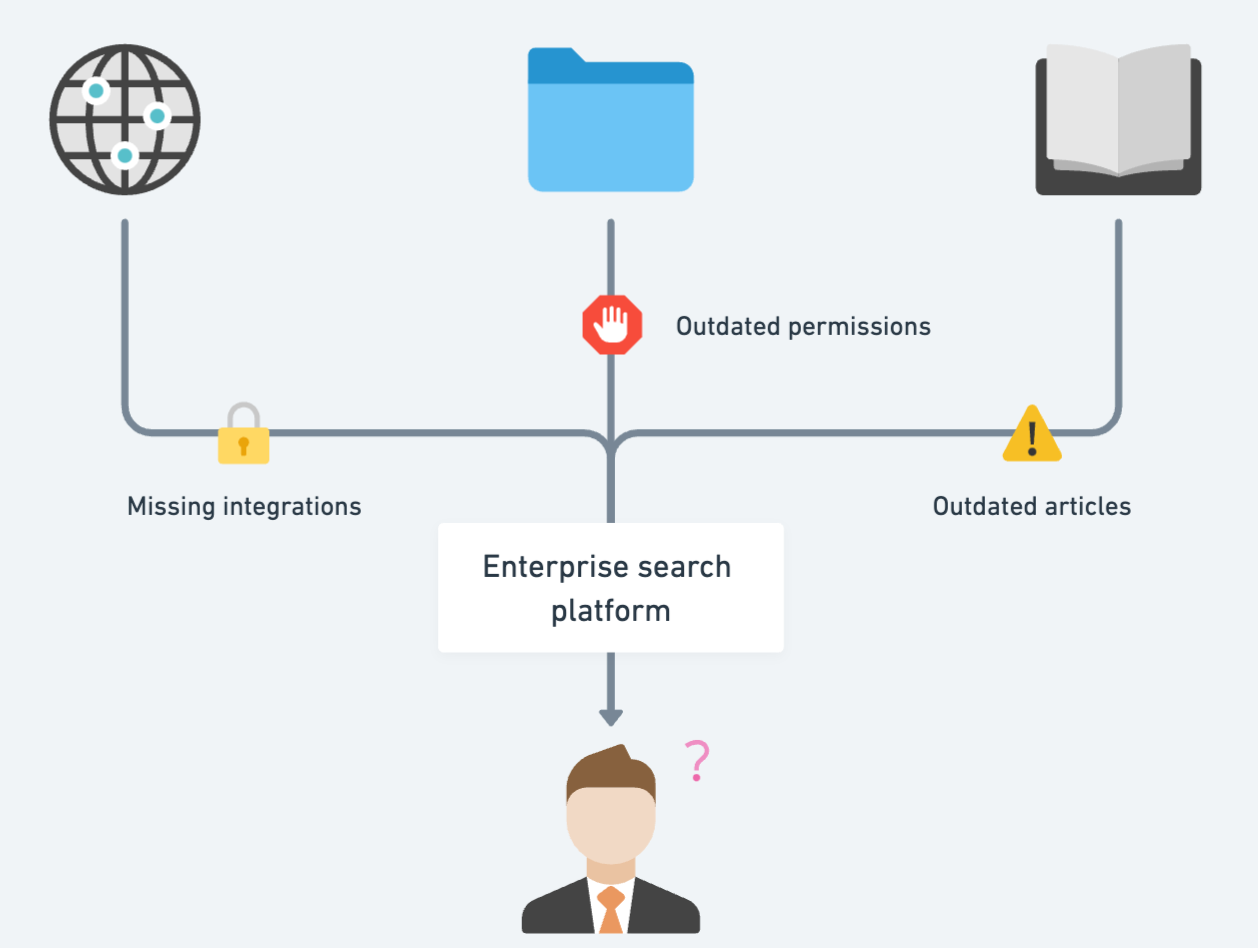
Some organizations try to bypass integrations & upload content on a one-time basis. But one-time content uploads don’t meet organization needs: since your content & permissions are ever-evolving. You want to ensure that your users follow the latest policies. You want to make sure that authorized users don’t see policies that they have lost access to.
As a result, even with an Enterprise Search platform — employees:
- Are unable to find important information (Missing integrations),
- Are served info they shouldn’t have access to (Outdated permissions) or
- Are served outdated info (Outdated articles)
To keep your Enterprise Search system in sync with your content system, your organization needs to build your own content integrations.
Organizations need data integrations but building them is painful & expensive for developers
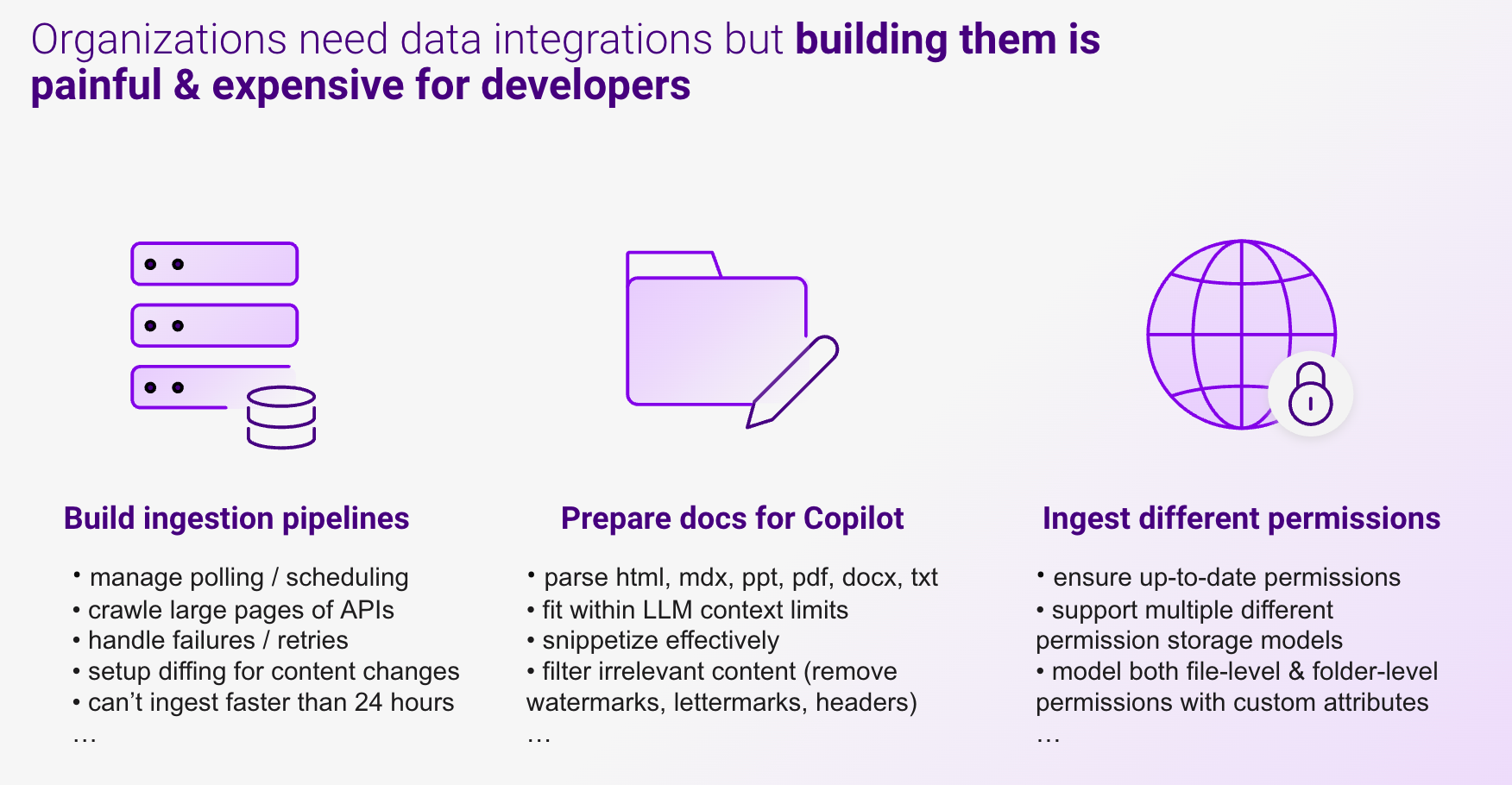
Building a content integration is no easy feat for developers & data engineers. Today’s approaches require a developer to be responsible for the end-to-end journey of building data pipelines. Developers need to own the following:
- Build robust ingestion pipelines: They need to manage polling / scheduling, crawling large pages of API responses (often 1000s of files per integration), handle failures / retries, setup diffing for content changes, deal with limitations to ingest faster than 24 hours. This setup requires significant infrastructural overhead & engineering expertise.
- Prepare docs for Copilot: Parsing logic for a ton of content types (html, mdx, ppt, pdf, docx, txt, more), make sure response is trimmed to fit within LLM context limits, snippetize the content to improve data presentation to users & improve Copilot’s semantic understand & filter irrelevant content (remove watermarks, lettermarks, headers). Developers often have to purchase & setup heavy “pdf to txt” or “OCR” libraries.
- Setup ingestion for complex permissions: You want to make sure users never access a file they don’t have access to. This means ensure up-to-date / near real-time permissions, support multiple different permission storage models (across file-level & folder-level permissions), support custom permission attributes. Permissions are often distributed across Content, Group & User tables in knowledge systems. Developers need to merge all this data to calculate final permissions — merging tables is often an expensive & flaky operation.
Building these data integration pipelines is an expensive process. Today, organization developers are burdened to manage this painful integration setup.
Content Gateway un-burdens developers from building data integrations
With the Content Gateway, developers no longer need to manage data infrastructure (when connecting knowledge systems to the Moveworks Enterprise Search platform). Content Gateway shifts the responsibilities from developers to the Moveworks platform:
Traditional Content Indexing | Content Gateway | |
1. Periodically retrieve content | Owned by Developers | Owned by Moveworks |
2. Crawl retrieved content | Owned by Developers | Shared responsibility |
3. Efficiently process changed content | Owned by Developers | Shared responsibility |
4. Parse many content types | Owned by Developers | Owned by Moveworks |
5. Pre-process content for Copilot Search | Owned by Developers | Owned by Moveworks |
6. Index content permissions | Owned by Developers | Shared responsibility |
7. Error handling & Retry logic | Owned by Developers | Owned by Moveworks |
Instead of building complex data pipelines and merging tons of data, Content Gateway empowers developers to build on top of pre-existing APIs that they use for managing content. Moveworks provides simple interfaces for developers to implement APIs that follow standard & re-usable oData practices.
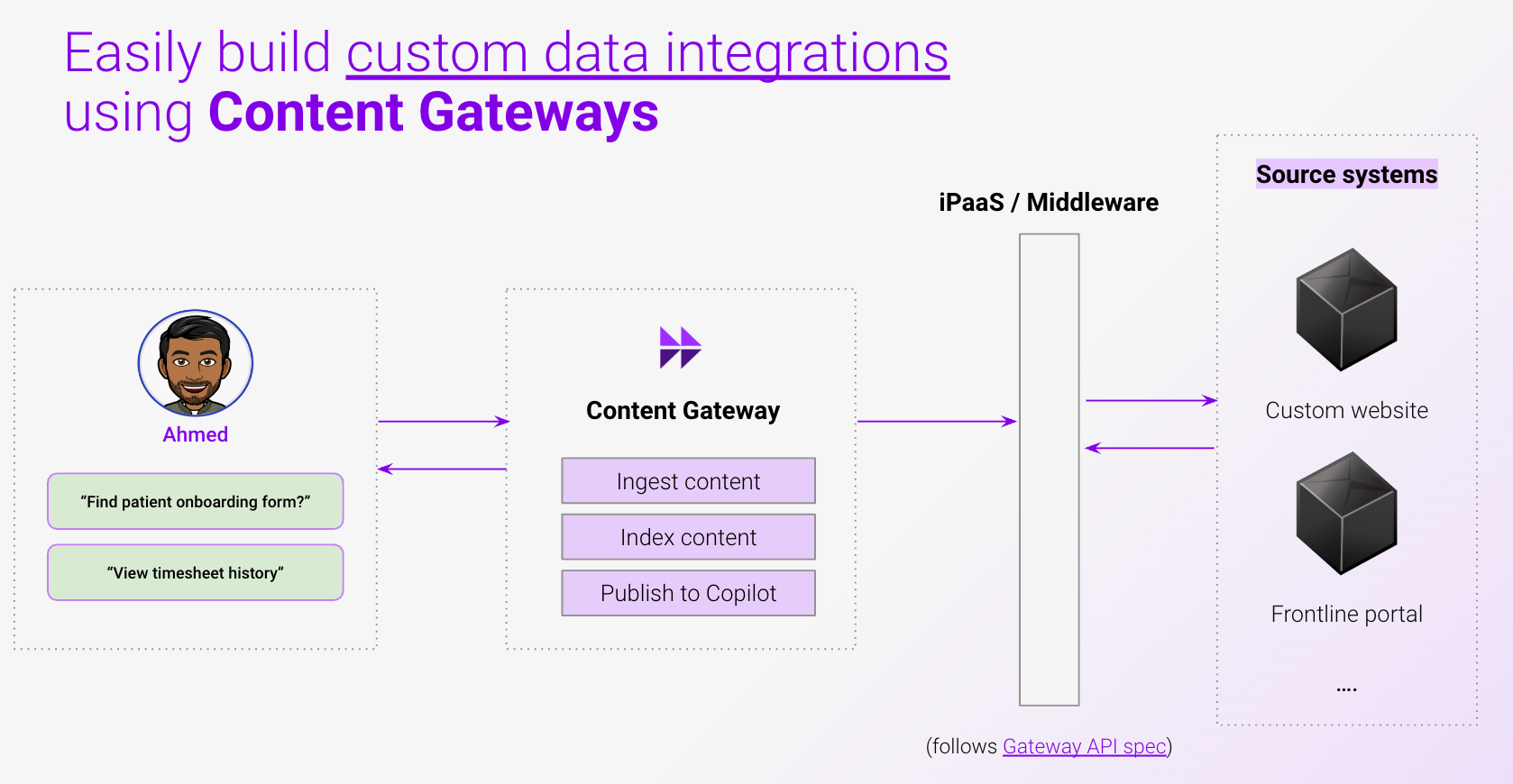
Moveworks then connects to these developer APIs through our enterprise-grade content & data ingestion platform. This data ingestion platform has many key benefits:
- End-to-end ingestion pipelines. Moveworks handles ingestion job scheduling, retries & errors, log management, document parsing, snippetization, and indexing. All your developers need to worry about is providing us the correct REST APIs. Note: This requires your developers to use an orchestration tool.
- Near real-time content: Moveworks provides multiple ingestion options. Depending on your need you can setup daily ingestion or ingestion that syncs with your source systems every few minutes. This means ability to keep content & permissions up-to-date in your Copilot.
- Integrated permissions: Moveworks Gateways can support & sync several complex permission types. Users will never be served content they shouldn’t have access to.
- Efficient ingestion: We reduce the burden on your system by only re-ingesting files that had detected changes. This means ingestion that is faster, more efficient & less likely to fail.
- Support for many content types: Content gateway will support KBAs, PDFs, DOCs, PPTs, TXTs content & more. We plan to further extend this support to more resource types such as identity, users, forms, tickets, custom resources, etc.
This Content Gateway approach makes it possible for your Copilot to be used enterprise-wide. It allows your employees to be more enabled & productive by using a search platform that spans across all your systems.
We’re excited to launch our content gateway’s first module, the file gateway, here. All your developers need to start is a server or iPaaS to host APIs!
Table of contents


